「海外からの問い合わせに対応したいけど、翻訳コストが高すぎる」「社内の多言語資料を横断検索できたら業務がもっと楽になるのに」——そんな悩みを抱えるスモールビジネスの方に注目してほしいのが、2026年6月にLiquid AIが公開した検索特化モデルLFM2.5です。
日本語を含む11言語に対応しながら、わずか3.5億パラメータという軽量設計で普段使いのPCでも動作します。
この記事では、LFM2.5の特徴から具体的な導入手順まで、スモールビジネスの多言語対応を効率化する方法をわかりやすく解説していきます。
- LFM2.5の基本的な仕組みと11言語対応の検索性能
- 翻訳なしで多言語検索を実現するクロスリンガル機能の特徴
- EmbeddingとColBERT、2つのモデルの違いと選び方
- 専門知識がなくても始められる具体的な導入ステップ
Liquid AIの検索モデルLFM2.5とは
2026年6月17日、AI企業Liquid AIが検索特化の新モデル「LFM2.5」を公開しました。日本語を含む11言語に対応し、スモールビジネスの多言語検索を根本から変える軽量モデルです。
11言語に対応する超高速な検索システム
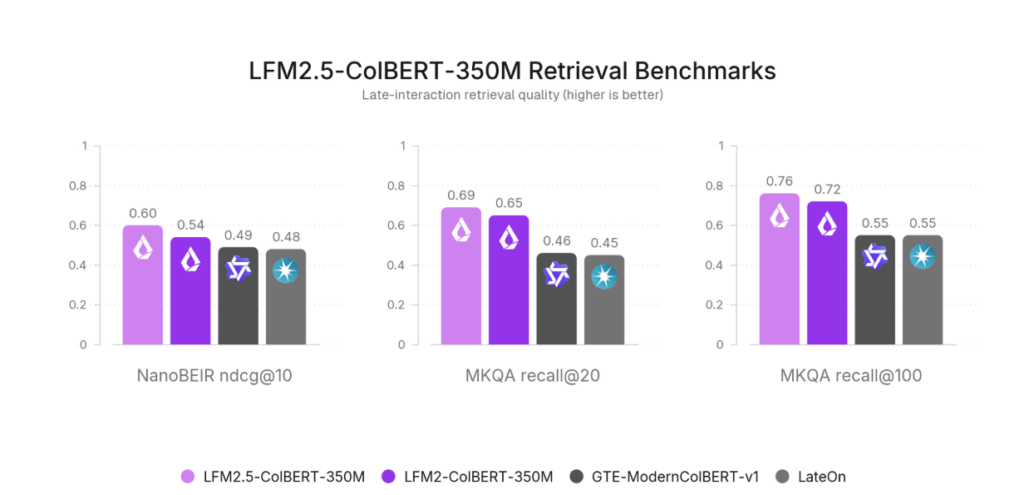
LFM2.5は、日本語・英語・韓国語など11言語で高精度な検索を実現するリトリーバーモデルです。今回発表された「LFM2.5-Embedding-350M」と「LFM2.5-ColBERT-350M」の2モデルは、わずか3.5億パラメータという軽量サイズながら、より大規模なQwen3-Embedding-0.6Bをベンチマークで上回る性能を叩き出しています。
 編集部
編集部GPU上での検索遅延は2ミリ秒未満、CPUやノートPCでも10ミリ秒未満で応答が返ってきます。
特に注目すべきは、エンドツーエンドの検索遅延が最短1.5ミリ秒という圧倒的なスピードです。従来の検索システムでは数秒かかっていた処理が、ほぼ体感ゼロの待ち時間で完了します。
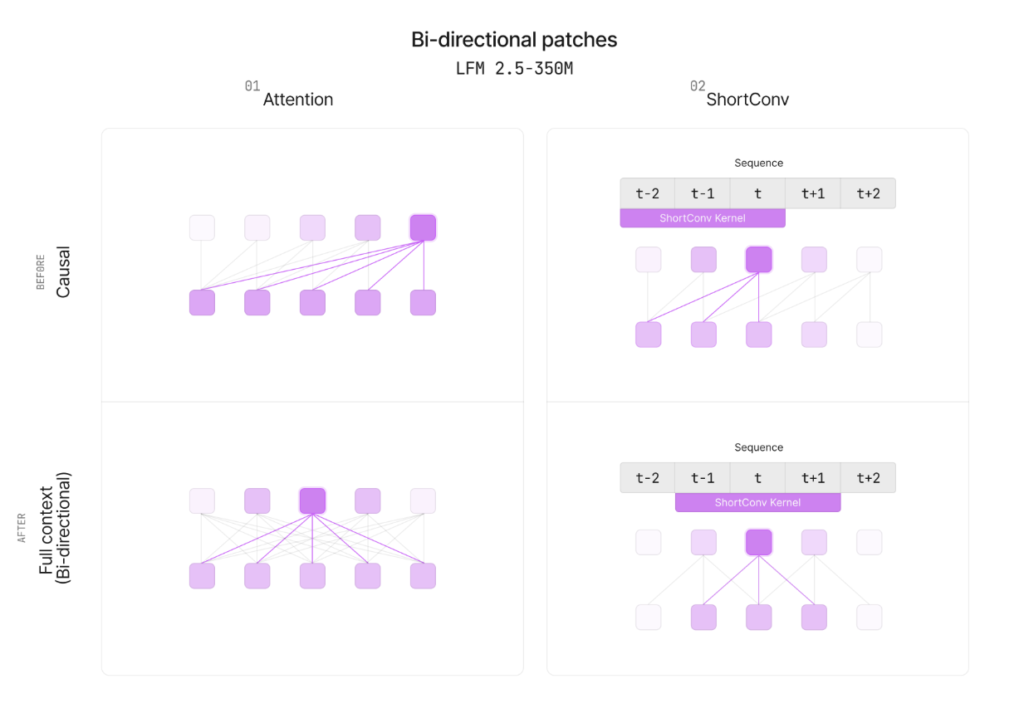
技術面では、LFM2.5シリーズ初の双方向エンコーダーを採用しており、クエリ全体の文脈を左右両方向から読み取ることで、検索意図をより正確に捉える設計になっています。アラビア語からスウェーデン語まで、どの言語でも一貫して最高クラスの検索品質を維持できる点が、グローバル展開を目指すスモールビジネスにとって大きな魅力です。
低コストで運用できる軽量なAI技術
LFM2.5の運用コスト面での強みは、高価なGPUやクラウド契約なしでも本格的なAI検索が動く点にあります。GGUF形式で配布されているため、llama.cppを使えば普段使いのノートPCやエッジデバイス上でほぼゼロコストで実行可能です。
LFM2.5が低コスト運用を実現できる具体的な理由は、以下のとおりです。
- パラメータ数3.5億で、量子化すると500MB未満に収まる
- MacBook M4 Maxで約7〜8ミリ秒の応答速度を出せる
- Apple・AMD・Intel・Qualcomm・Nvidiaの各チップにネイティブ対応している
- オープンウェイトで制限なくダウンロード・カスタマイズ・運用できる
さらに、自社データでのファインチューニングも手軽に行えます。Hugging Faceのモデルカードにはsentence-transformersを使ったコードが用意されており、製品カタログやFAQなど業種固有の情報に最適化することで検索精度を引き上げられます。
編集部クラウドAIに月数十万円払っていた検索コストが、ローカル運用ならほぼゼロになるケースもあります。
GPU・CPU・スマートフォン・車載システムまで、あらゆるデバイスで動作する柔軟性を備えているため、スモールビジネスが自社の環境に合わせて無理なく導入できる点も見逃せません。
LFM2.5で多言語対応を効率化する理由
多言語対応に翻訳コストや手間がかかるのは、スモールビジネス共通の悩みです。LFM2.5はその課題を技術面から根本的に解消してくれます。
翻訳不要で海外データも瞬時に検索可能
LFM2.5の最大の強みは、言語の壁を越えて直接ドキュメントを検索できるクロスリンガル機能です。たとえば日本語で検索クエリを入力しても、英語やドイツ語、韓国語で書かれた資料から関連情報をそのまま引き当てられます。
従来の多言語検索では「クエリを翻訳→検索→結果を再翻訳」という複数ステップが必要で、時間もコストもかかるうえに翻訳ミスによる情報の取りこぼしが避けられませんでした。
編集部MKQA-11ベンチマークではRecall@20で0.69を達成し、クロスリンガル検索の実力が数値でも裏付けられています。
LFM2.5がこの精度を実現できるのは、3段階の学習プロセスで11言語の意味表現を統合しているからです。第2段階では強力な教師モデルからの多言語蒸留を行い、言語間で共通の意味空間を構築しています。この仕組みにより、海外の製品カタログや多言語FAQを原文のまま保持しながら単一の検索窓から瞬時にアクセスでき、グローバル展開時の翻訳コストを大幅にカットできます。
顧客の検索意図を理解し正確に回答する
LFM2.5はキーワードの一致だけでなく、顧客が本当に知りたいことを意味レベルで理解して検索結果を返せるモデルです。この能力を支えているのが双方向エンコーダーで、クエリ内のすべての単語が左右両方の文脈を参照できるため、文全体の意図を的確に把握できます。
LFM2.5-ColBERT-350Mが意図理解に強い理由は、以下の仕組みにあります。
- 各トークンを個別の128次元ベクトルに変換して単語単位で照合する方式
- MaxSimによる後期相互作用で細かい意味の違いまで捉える設計
- NanoBEIRベンチマークでNDCG@10が0.605と大規模モデルを上回る精度
編集部「返品方法」「配送料」「保証期間」など具体的な質問でも、条件に合う回答を正確に引き当てられます。
さらに重要なのは、11言語すべてで検索品質が落ちない一貫性を持っている点です。英語以外の言語で精度が下がるモデルが多いなか、LFM2.5はアラビア語から日本語、スウェーデン語まで同水準の回答精度を維持しており、多国籍の顧客対応でも言語による品質差が生まれません。自社データでファインチューニングすれば、業種特有の検索パターンにも最適化できます。
スモールビジネス向けLFM2.5の活用法
限られた人員と予算で業務を回すスモールビジネスにとって、LFM2.5は社内業務と顧客対応の両面で即戦力になる技術です。
社内文書の検索速度向上とコスト削減
LFM2.5を社内文書検索に導入すれば、検索速度の大幅な改善と運用コストの削減を同時に実現できます。従来のクラウドAI検索では月に数十万円の利用料が発生し、検索レスポンスも数秒かかるのが一般的でした。
LFM2.5はGGUF形式でローカル実行に対応しているため、社内サーバーや社員のPC上で動かせばクラウド利用料はゼロになります。
編集部文書の埋め込みを事前計算しておけば、クエリ応答は10ミリ秒未満で返ってきます。
この超高速検索により、社員がマニュアルや法務文書、技術ドキュメントから必要な情報を探す時間は劇的に短くなります。
機密データを外部に送信せずローカルだけで完結するため、顧客情報や財務データなど社外に出せない情報を扱う企業でも安心して運用可能です。多言語で書かれた社内資料も翻訳なしで横断検索でき、グローバル拠点を持つスモールビジネスの情報共有にも直結します。
顧客サポートの自動化で業務負担を軽減
LFM2.5をFAQ検索やチャットボットに組み込めば、顧客対応の大部分を自動化して担当者の負担を減らせます。製品カタログやサポートドキュメントなど短コンテキストの検索に特化しており、顧客からの質問に対して最も関連性の高い回答を瞬時に提示してくれます。
LFM2.5が顧客サポート自動化に向いている理由は、以下の点にあります。
- 11言語で検索品質が落ちず多国籍の顧客に同水準で対応可能
- エンドツーエンドの応答遅延が1.5〜10ミリ秒未満で体感待ち時間ほぼゼロ
- ローカル実行で顧客の個人情報を外部に出さずプライバシーを保護
編集部24時間365日、担当者不在でも即時回答できる体制が低コストで整います。
スモールビジネスでは1人の担当者が複数の業務を兼任するケースが多く、問い合わせ対応に追われて本来の業務が進まないという悩みは珍しくありません。LFM2.5を活用すれば、よくある質問への回答を自動化しつつ、休眠顧客への再アプローチにも検索データを活かせるため、限られたリソースでも顧客との接点を維持・拡大できます。
LFM2.5の2つのモデルの違いと選び方
LFM2.5にはEmbeddingとColBERTの2モデルがあり、用途に応じた使い分けが検索システムの効果を大きく左右します。
速度と軽さに特化したEmbedding
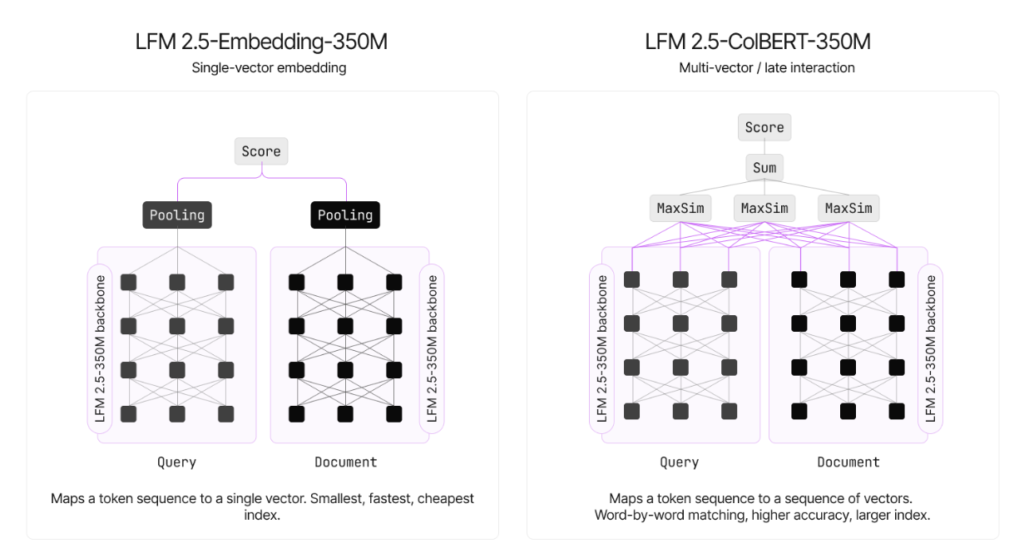
LFM2.5-Embedding-350Mは、文書全体を1つの1024次元ベクトルに圧縮する方式を採用しており、最速の検索スピードと最小のインデックスサイズを両立したモデルです。CLSスタイルのプーリングで単一の密な埋め込みを生成するため、ストレージコストを最小限に抑えながら大量のクエリをリアルタイムで処理できます。
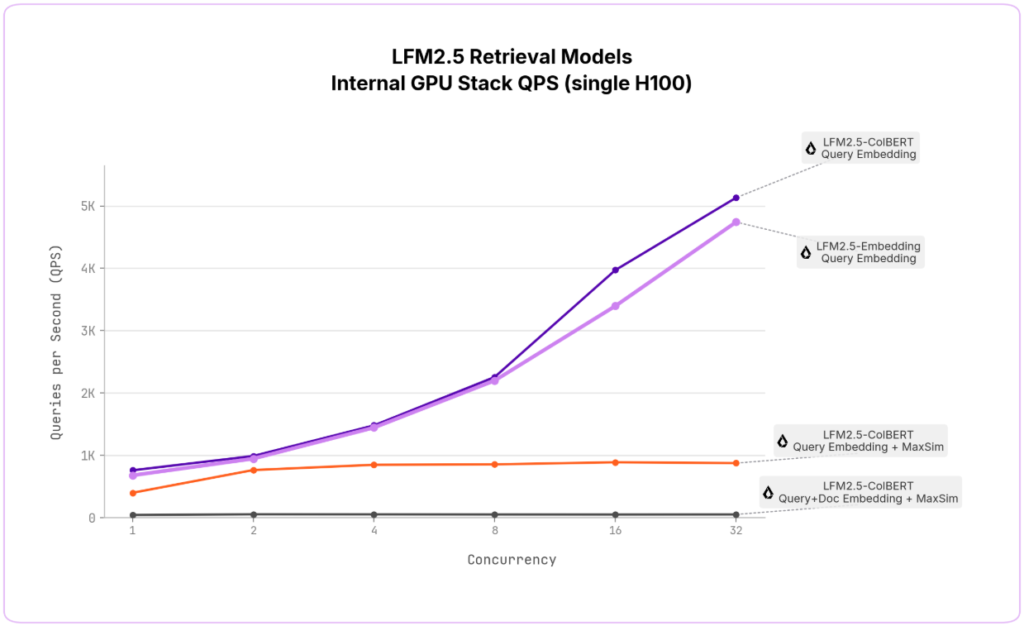
編集部H100 GPUで約2.5ミリ秒、MacBook M4 Maxでも約7〜8ミリ秒の応答速度を実現しています。
オンラインストアの製品検索やFAQシステムなど、ユーザーを待たせたくない場面で特に力を発揮します。量子化すれば500MB未満に収まるため、スマートフォンやエッジデバイスでの運用にも対応可能です。
迅速なレスポンスが求められるユースケースでは、まずこのEmbeddingモデルから導入を検討するのが合理的な判断になります。コストと速度を最優先にしたいスモールビジネスに最適な選択肢です。
高い検索精度を誇るColBERTモデル
LFM2.5-ColBERT-350Mは、文書内の各トークンを個別に128次元ベクトルへ変換し、単語レベルで照合する方式を採用しています。Embeddingモデルが文書全体を1つのベクトルにまとめるのに対し、ColBERTはMaxSimによる後期相互作用で細かい意味の違いまで捉えられるため、より高い精度と汎化性能を持っています。
ColBERTモデルが精度面で優れている理由は、以下の仕組みにあります。
- 複数ベクトルによるきめ細かいマッチングで意味の取りこぼしが少ない
- NanoBEIRベンチマークでNDCG@10が0.605と大規模モデル超えの実績
- MKQA-11クロスリンガルQAでもRecall@20が0.69を達成
編集部インデックスサイズはEmbeddingより大きくなりますが、精度重視の場面ではその差を補って余りある性能です。
技術サポートの問い合わせ対応や、複雑な条件を含む顧客の質問に正確に答えたい場面ではColBERTが適しています。両モデルとも同じ3.5億パラメータで動作環境も共通なので、速度優先のページにはEmbedding、精度優先の機能にはColBERTと併用する運用も十分に現実的です。
LFM2.5導入でスモールビジネスを強化
LFM2.5は専門的な開発環境がなくても導入でき、既存の業務フローにすぐ組み込める手軽さがスモールビジネスにとっての大きな魅力です。
既存システムへ簡単に導入するステップ
LFM2.5の導入は、LM Studioをインストールしてモデルをダウンロードするだけで始められます。LM Studioの公式サイトからインストーラーを取得し、起動後に「LFM2.5」と検索すれば目的のモデルが見つかります。
モデルファイルは約720MB〜1GB程度で、従来の大規模モデルが数十GB必要だったことを考えると非常にコンパクトです。
編集部GGUF形式で提供されているため、高価なGPUがなくても普段使いのPCやノートPCで動作します。
既存のウェブサイトやデータベースとの連携も、llama-serverコマンドでAPIサーバーとして起動しHTTP経由で接続するだけで完了します。製品検索バーやFAQページ、チャットボットなど、すでにある顧客接点にそのまま組み込めるため、システムを一から作り直す必要はありません。
オープンウェイトで制限なくカスタマイズ・運用が可能なので、Apple・AMD・Intel・Nvidiaなど使用中のハードウェアを問わず柔軟に対応できます。
専門知識なしで始めるAI検索の第一歩
LFM2.5を使い始めるのに、AIや機械学習の専門知識は一切必要ありません。LM Studioの画面上でモデルを選択し、チャット欄に質問を入力するだけで、11言語のドキュメントから関連情報を自動で検索・表示してくれます。
具体的な活用の始め方は、以下の3ステップだけです。
- LM Studioをインストールしてアプリを起動
- LFM2.5モデルを検索しダウンロード
- チャット画面で製品検索やFAQ検索を試す
編集部GPUなしのPC環境でも毎秒70トークン級の推論速度が出るため、低スペック端末でも実用的に動きます。
通常のチャットアプリと同じ感覚で操作できるので、ITに詳しくないスタッフでもすぐに使いこなせます。ローカル実行で機密データを外部に出さずに済むため、顧客情報のプライバシー保護を重視する企業にも適しています。クラウドAIに頼らず、社内だけで完結する完全無料のAI検索環境をまずは試してみるところから始めてみてください。
まとめ
この記事では、Liquid AIが2026年6月17日に公開した検索特化モデル「LFM2.5」について、特徴やスモールビジネスでの活用法を詳しく解説しました。
ポイントを簡潔にまとめると以下の通りです。
- 3.5億パラメータの軽量モデルで日本語を含む11言語の検索に対応
- 翻訳不要のクロスリンガル検索で多言語対応のコストを大幅カット
- LM Studioを使えば専門知識なし・GPU不要で即日導入が可能
LFM2.5は、速度重視のEmbeddingモデルと精度重視のColBERTモデルの2種類が用意されており、用途に応じた使い分けができます。どちらもローカル環境で動作するため、機密データを外部に出さずに運用できる点もスモールビジネスにとって安心です。
まずは無料で試すなら、LM Studioをインストールしてモデルをダウンロードするだけで始められます。自社のFAQや製品カタログで検索精度を体感してみると、導入後のイメージが掴みやすくなるはずです。
また、Hugging Faceでは自社データでのファインチューニング用コードも公開されているので、ぜひチェックしてみてください。
参照元:
- https://www.liquid.ai/blog/lfm2-5-retrievers
- https://www.marktechpost.com/2026/04/11/liquid-ai-releases-lfm2-5-vl-450m-a-450m-parameter-vision-language-model-with-bounding-b/
- https://www.youtu.be.com/watch?v=FyN7bPVTJ5M
- https://www.weel.co.jp/media/tech/lfm2-5/
- https://www.qiita.com/uoura/items/19cca471a6cc3a733f42
- https://www.note.com/kind_orchid920/n/nee88b9b1ae2f