

スモールビジネスの業務を自動化したいけれど、AIツールは高額で手が出せないとお悩みではありませんか?
GLM-4.7-Flashは、2026年1月19日にZ.aiがリリースした軽量高速モデルで、API料金が競合の3分の1以下という破格の設定を実現しています。
エンジニアを雇う余裕がなくても、自然言語で指示するだけで顧客対応ツールや売上レポートを自動生成でき、月数千円の予算で常時稼働する業務自動化が可能になります。
この記事では、GLM-4.7-Flashの特徴からGPT-OSS-20Bとの性能比較、具体的な導入手順まで詳しく解説していきます。
- GLM-4.7-Flashの基本スペックと軽量高速モデルとしての特徴
- GPT-OSS-20Bとのベンチマーク比較で見える性能の違い
- チャット履歴や売上レポートなど業務自動化への具体的な活用法
- API版GLM-4.7-FlashXの導入手順とノーコード連携の方法
GLM-4.7-Flashとは?特徴と用途を徹底解説
GLM-4.7-Flashは2026年1月19日にZ.aiがリリースした軽量高速モデルで、スモールビジネスの業務自動化に最適な性能とコストを両立しています。
軽量・高速モデルのスペックと基本情報
GLM-4.7-Flashは、30Bパラメーターを持ちながらMoEアーキテクチャで約3Bのみを活性化する設計を採用しており、少ないリソースで高い処理能力を発揮します。コンテキスト長は128Kトークンに対応し、約10万語相当の長文を一度に処理できるため、業務マニュアルやチャット履歴の分析にも向いています。
 編集部
編集部通常のモデルより少ないメモリで動くため、自社PCでも運用しやすいのが特徴です。
API料金は入力1Mトークンあたり0.07ドル、出力0.40ドルと競合より大幅に低コストで、vLLMやSGLangなどのフレームワークがすでにサポートしているため、ローカル環境への導入も容易に進められます。
スモールビジネスが注目する理由とは
スモールビジネスがGLM-4.7-Flashに注目する最大の理由は、高性能を低コストで手に入れられる点にあります。エンジニアを雇う余裕がない小さな現場でも、自然言語の指示から業務ツールを即座に生成できるのは大きな魅力です。
注目される具体的なポイントは以下のとおりです。
- SWE-bench Verifiedで同サイズのオープンソース最先端を達成
- ツール呼び出しや構造化出力の機能が強化済み
- Google SheetsやLINEとの連携が容易
編集部プログラミング初心者でも「自社専用AI」を低リスクで構築できます。
これらの特徴により、月数千円の予算で常時稼働する自動化を実現し、オーナーが本業の成長戦略に集中できる環境が整います。
GPT-OSS-20Bとの性能比較で見えるGLM-4.7-Flashの優位性
GLM-4.7-Flashは複数のベンチマークでGPT-OSS-20Bを上回る結果を出しており、オープンウェイトによる自由度の高さも大きな強みです。
コーディング・業務自動化分野でのベンチマーク結果
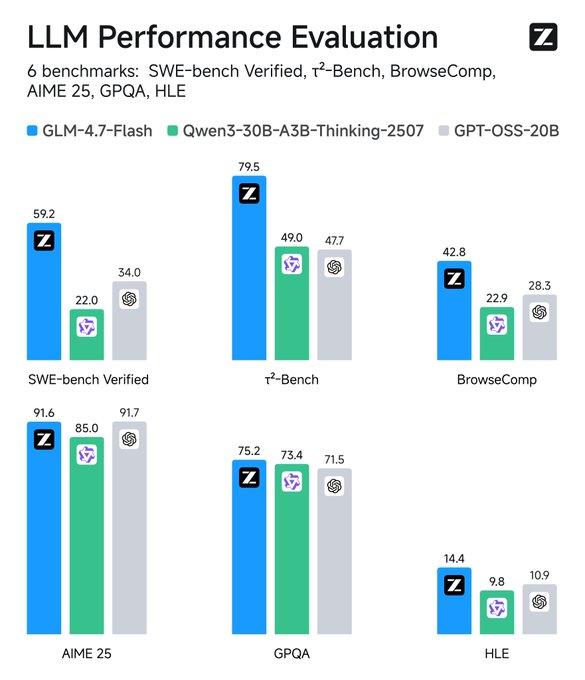
GLM-4.7-Flashは、実務レベルのコーディングや業務自動化でGPT-OSS-20Bを明確に上回るスコアを複数記録しています。SWE-bench Verifiedでは59.2%を達成し、GPT-OSS-20Bの34.0%に対して25ポイント以上の差をつけました。
編集部このテストは実際のGitHubリポジトリのコードを修正する厳しい内容です。
τ²-Benchでも79.5%対47.7%と約32ポイントのリードを示しており、多段階のツール実行タスクで高い安定性を発揮しています。LiveCodeBench v6では64.0%でGPT-OSS-20Bの61.0%を僅かに上回り、日常的なプログラミングタスクでも信頼できる性能を証明しました。
オープンウェイトでの利便性と自由度の高さ
GLM-4.7-Flashの強みは、モデルウェイトを公開しMITライセンスで商用利用を許可している点にあります。GPT-OSS-20Bの閉鎖的な運用とは対照的で、スモールビジネスにとって柔軟な選択肢を提供してくれます。
オープンウェイトによる具体的なメリットは以下のとおりです。
- Hugging Faceや自社サーバーへのダウンロードが可能
- vLLMやSGLangでの高速推論に対応
- 業務データを使ったファインチューニングが自由
編集部API料金をゼロに近づけながら自社専用にカスタマイズできます。
量子化により12GB VRAMのPCでも動作するため、インフラ投資を抑えつつ長期的なコスト管理がしやすく、プライバシーを重視する事業者にも適しています。
業務自動化に最適なAIエージェントとしての活用法
GLM-4.7-Flashは128Kトークンの長大なコンテキストを処理でき、チャット履歴の分析から売上レポート作成まで幅広い業務に対応します。
チャット履歴やマニュアルの処理能力を活かす方法

GLM-4.7-Flashは128Kトークンのコンテキストウィンドウを備えており、過去のチャット履歴や業務マニュアル全体を一度に読み込んで処理できます。
数ヶ月分の顧客とのLINEやメールのやり取りを丸ごと入力すれば、AIが傾向を分析して「よくある問い合わせパターン」を抽出してくれます。
編集部プロンプトで「過去のやり取りから優先度を分類して」と具体的に指示するのがコツです。
店舗のオペレーションマニュアルをアップロードし、「この手順に基づいて顧客対応フローをコード化して」と頼めば、即座に動作するスクリプトを出力できます。散在する情報をAIに記憶させることで、日々の判断ミスを減らし一貫したサービス品質を保てるようになります。
売上レポートや請求処理など現場への実装ポイント
売上レポートの自動化では、Google SheetsやCSVのデータを渡して自然言語で指示するだけで集計やグラフ付きレポートを生成できます。
実装時に押さえておきたいポイントは以下のとおりです。
- API経由でデータを定期送信する簡単なスクリプトを作成
- 出力されたJSONをスプレッドシートに自動反映
- 温度設定を0.7に固定して安定性を確保
編集部毎月の手作業が5分に短縮され、数字から戦略をすぐに導けます。
請求処理では「過去請求書のフォーマットを読み込み、新規データから請求書PDFを生成して」と頼めば、エージェント機能が複数ステップを一括実行してくれるため、少人数のスモールビジネスでもバックオフィス業務を効率化できます。
API版「GLM-4.7-FlashX」での導入手順とコスト比較
GLM-4.7-FlashXは並列処理に特化したAPI専用バージョンで、破格の料金設定とノーコードツールとの連携でスモールビジネスにも導入しやすい仕様です。
API料金と他モデルとのコストパフォーマンス比較
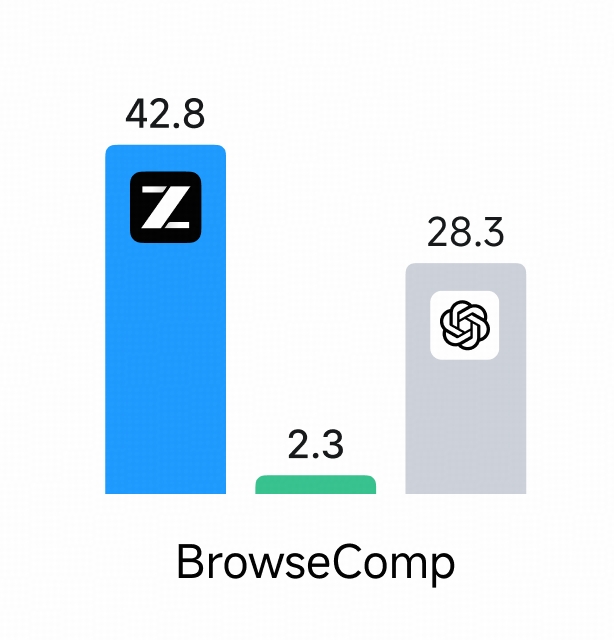
GLM-4.7-FlashXは、入力1Mトークンあたり0.07ドル、出力0.40ドルという破格の料金設定を実現しています。GPT-OSS-20Bで同等のタスクを処理する場合と比べて、コストは3分の1以下に抑えられます。
編集部月間10万トークン処理でも数百円で済むため、常時稼働の自動化も現実的です。
FlashXの特長は同時リクエストの無制限並列処理にあり、通常のFlash版が1〜3リクエストに制限されるのに対して、200件以上のバッチ処理を安定して実行可能です。
GPT-4o-miniの入力料金0.15ドルと比較しても半額以下で、同等以上のコーディング精度を提供してくれるため、成長中のスモールビジネスが予算内でスケールアップしやすい設計になっています。
ノーコード連携によるスモールビジネス導入法
GLM-4.7-FlashXの導入は、Z.ai開発者コンソールでAPIキーを取得し、ZapierやMake.comのノーコードツールにHTTPモジュールを追加するだけで完了します。
導入時に設定しておきたい項目は以下のとおりです。
- Google Sheetsの新行追加をトリガーに設定
- 温度0.7とthinkingモードをオンに指定
- JSON出力形式で連携をスムーズに
編集部プログラミング不要で業務フローの自動化が始められます。
実装の進め方としては、まず単一タスクを1週間の無料枠で検証し、効果を確認してから有料プランへ移行するのがおすすめです。LINE公式アカウントやNotionと組み合わせれば、顧客メッセージの自動要約からアクション登録まで一気通貫で実現でき、エンジニア不在でも1日で「AI業務代行システム」を立ち上げられます。
GLM-4.7-Flash導入で得られる業務改善と将来展望
GLM-4.7-Flashは軽量設計により少人数でも自社運用が可能で、オープンウェイトの特性を活かしてベンダーに依存しない柔軟なAI活用を実現できます。
少人数体制でも自社運用が可能になる理由
GLM-4.7-Flashは30BパラメーターながらMoEアーキテクチャで軽量化されており、標準的なGPUサーバーや自社PCでも動作します。vLLMやSGLangといったオープンソースフレームワークを使えば、12GB VRAMのマシンで量子化版を即デプロイ可能です。
編集部API依存を脱して24時間稼働の業務自動化を実現できます。
初期ハードルはモデルダウンロードと環境構築だけで、一度セットアップすれば月額電気代数百円で高性能AIを独占運用できます。
月3ドルからのZ.aiライトプランと併用することで、プロトタイプから本格運用への移行もスムーズに進められ、エンジニア不在の現場でも予約管理や顧客対応ツールを自前でメンテナンスできるようになります。
ベンダーロックインを避けた柔軟なAI戦略の構築
GLM-4.7-FlashはオープンウェイトとMITライセンスにより自社データでのファインチューニングが可能で、将来的に他モデルや自社アルゴリズムとのハイブリッド運用も容易に行えます。
柔軟な戦略を構築するうえでのポイントは以下のとおりです。
- Z.aiのAPIに縛られずオンプレミスやVPC展開を選択可能
- データプライバシーを守りながら成長に応じてスケールアップ
- 他社サービス終了リスクを回避した長期的なAI投資
編集部無料のオープンウェイト版でコア業務を固め、FlashX APIを補助的に活用する二段構えが効果的です。
この進め方により、独自の業務知識をAIに学習させて他社との差別化ツールを育てる柔軟性が手に入り、競合に先駆けたデジタル変革を低リスクで進められます。
まとめ
この記事では、Z.aiが2026年1月19日にリリースした軽量高速モデル「GLM-4.7-Flash」の特徴や、スモールビジネスでの業務自動化への活用法について詳しく解説しました。
ポイントを簡潔にまとめると以下の通りです。
- 30BパラメーターながらMoEアーキテクチャで約3Bのみ活性化し、少ないリソースで高性能を発揮
- API料金は入力1Mトークンあたり0.07ドル、出力0.40ドルと競合より大幅に低コスト
- オープンウェイトかつMITライセンスで、自社サーバーへのローカル展開やファインチューニングが自由
GLM-4.7-Flashは、128Kトークンの長大なコンテキストを処理でき、チャット履歴の分析から売上レポート作成まで幅広い業務に対応します。SWE-bench Verifiedで59.2%を達成するなど、コーディングや業務自動化のベンチマークでGPT-OSS-20Bを上回る結果を出しています。
低コストで始めるなら、API版のGLM-4.7-FlashXがおすすめです。ZapierやMake.comなどのノーコードツールと連携すれば、プログラミング不要で業務自動化を始められます。
また、オープンウェイトの特性を活かしてベンダーロックインを避けた柔軟なAI活用もできるので、ぜひ自社の業務効率化に取り入れてみてください。
参照元:







コメント